The data set was collected from a collection of articles and book chapters found through CUNY OneSearch. Other collections were considered – including JSTOR or MLA. Ultimately, the decision was made to use CUNY OneSearch because it offered the greatest ease of use and access. OneSearch allows the user to filter searches by which texts are fully available through The Graduate Center, where I am a student. Because this project necessitates having access to full texts, this streamlined the data collection process considerably. Given the short time available to complete the project, and the positioning of the project as a teaching-tool rather than a published piece of academic research, this felt like the right position.
However, this choice did limit the data set in several ways. First, CUNY OneSearch searches metadata and titles, not full texts. This is helpful if you are looking for the most relevant works to your research topic, but for a project using a zoomed-out approach like this one it means that you are potentially missing articles that could have contributed to your dataset. Having fewer articles makes the project more manageable and less time consuming, but it may also be less accurate. Using CUNY OneSearch is also limiting, and biased, because you are only seeing articles that The Graduate Center has full digital access to. Choosing to limit your project to these sources means that your research is already biased by the access decisions made by the university: decisions which may be financial, political, or quality based. A more thorough approach would be to use JSTOR or MLA, and then use Interlibrary Loans to gain access to articles and books not directly available through the Graduate Center. This method would also include works that had not been digitized. It is, however, a vastly more time consuming approach.
My search terms in OneSearch were “The Tempest” + Shakespeare + Ariel. I applied filters limiting the search to articles, books, book chapters, and dissertations where the full text was available online (this also removed results for audio and visual documents). The resulting data set was 104 documents.
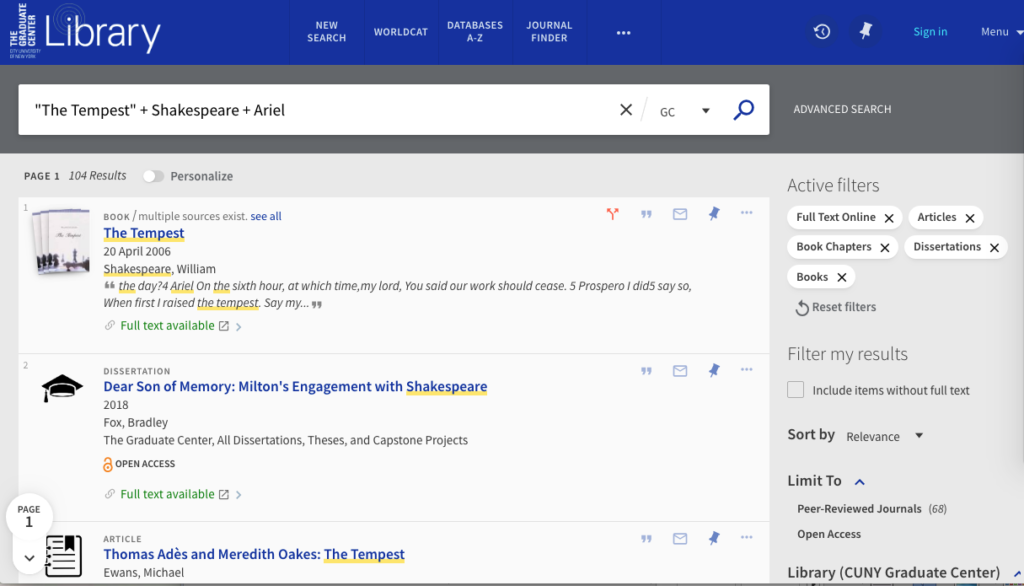
My next step was to download all the articles as PDFs. I had to do this manually, going through the search results and grabbing them one by one. This process was slow and laborious, but it had the benefit of acting as a second round filter. In this stage of the process I caught many articles that were unsuitable for this project (for instance, articles about productions or other interpretations of The Tempest that didn’t discuss the original text), and also a significant number of duplicate entries. I should also note here that I did not catch every unsuitable article during this step in the process, and continued to refine the data set into the next steps. I ended up with a data set that was culled from 104 results to 39 pdf files.
Continue on to the next section…

This entry is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International license.